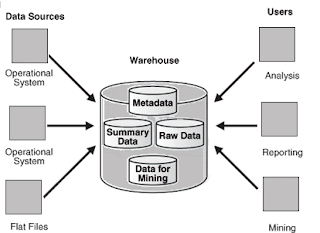
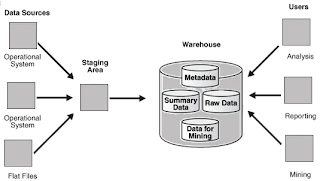
Data warehouse is designed mainly to supply Information to the business to decide in a better and faster way based on analysis of historical data. So it is essential we model its Logical and Physical design in the best way. Physical design is mainly for the purpose of performance and functionality of the data warehouse and logical design is a way to capture and present the business requirements in the entity way.
In data modeling following tasks are performed in an iterative manner:
• Identify entity types
• Identify attributes
• Apply naming conventions
• Identify relationships
• Apply data model patterns
• Assign keys
• Normalize to reduce data redundancy (Entity Relationship Model)
• Denormalize to improve performance (Dimensional Model)
In data modeling following tasks are performed in an iterative manner:
• Identify entity types
• Identify attributes
• Apply naming conventions
• Identify relationships
• Apply data model patterns
• Assign keys
• Normalize to reduce data redundancy (Entity Relationship Model)
• Denormalize to improve performance (Dimensional Model)
Two types of data modeling are as follows:
· Logical modeling
· Physical modeling
· Logical modeling
· Physical modeling
Logical modeling deals with gathering business requirements and converting those requirements into a model. The logical model revolves around the needs of the business, not the database, although the needs of the business are used to establish the needs of the database. Logical modeling involves gathering information about business processes, business entities (categories of data), and organizational units. After this information is gathered, diagrams and reports are produced including entity relationship diagrams, business process diagrams, and eventually process flow diagrams. The diagrams produced should show the processes and data that exists, as well as the relationships between business processes and data. Logical modeling should accurately render a visual representation of the activities and data relevant to a particular business.
Typical deliverables of logical modeling include
Entity relationship diagrams :
An Entity Relationship Diagram is also referred to as an analysis ERD. The point of the initial ERD is to provide the development team with a picture of the different categories of data for the business, as well as how these categories of data are related to one another.
Business process diagrams :
Business process diagrams :
The process model illustrates all the parent and child processes that are performed by individuals within a company. The process model gives the development team an idea of how data moves within the organization. Because process models illustrate the activities of individuals in the company, the process model can be used to determine how a database application interface is design.
User feedback documentation :
User feedback documentation :
Physical modeling involves the actual design of a database according to the requirements that were established during logical modeling. Logical modeling mainly involves gathering the requirements of the business, with the latter part of logical modeling directed toward the goals and requirements of the database. Physical modeling deals with the conversion of the logical, or business model, into a relational database model. When physical modeling occurs, objects are being defined at the schema level. A schema is a group of related objects in a database. A database design effort is normally associated with one schema.
During physical modeling, objects such as tables and columns are created based on entities and attributes that were defined during logical modeling. Constraints are also defined, including primary keys, foreign keys, other unique keys, and check constraints. Views can be created from database tables to summarize data or to simply provide the user with another perspective of certain data. Other objects such as indexes and snapshots can also be defined during physical modeling. Physical modeling is when all the pieces come together to complete the process of defining a database for a business.
Physical modeling is database software specific, meaning that the objects defined during physical modeling can vary depending on the relational database software being used. For example, most relational database systems have variations with the way data types are represented and the way data is stored, although basic data types are conceptually the same among different implementations. Additionally, some database systems have objects that are not available in other database systems.
Typical deliverables of physical modeling include the following:
Server model diagrams:
The server model diagram shows tables, columns, and relationships within a database.
User feedback documentation :
User feedback documentation :
Database design documentation :
Designing the Data warehouse
Main emphasis in the design is on fast query retrieval rather than transactional performance. The design should be such that it enables analysis of data from any angle at any given point of time.
Dimensional Data Model is the best way of designing a data ware house. The main terms used in dimensional modeling are facts and dimensions.
1. Fact - A fact is a single iteration in a historical record
2. Dimension - A dimension is something used to dig into, divide, and collate those facts into something useful
Facts represent historical or archived data and dimensions represent smaller static data entities. It follows that dimension entities will generally be small and fact entities can become frighteningly huge. Fact entities will always be appended to, and dimension entities can be changed, preferably not as often as the fact entities are appended to. The result is many very small entities related to data in groups from very large entities.
Granularity
While designing a fact the most important point to keep in mind is the granularity, how much data to keep and to what level of detail. So do we need to store all transaction or do we store it at summary level. Like in case of a Retailer and Manufacturer, a Retailer would like to capture each and every piece of an item sold from its point of sale i.e. at the lowest Stock keeping unit level to maintain its inventory better, where as the Manufacturer might keep it at a level higher than the pieces, they would not need information of each piece sold, they might be interested to keep record at an Item level, one level above Stock keeping as compared to Retailers. So depending on business needs we need to decide the lowest possible granular level to be kept in facts to make the reporting accurate. From a planning perspective, it might be best to begin by retaining all facts down to the smallest detail if at all possible. Data warehouses are expected to be large, and disk space is cheap.
Star and Snow Flake Schema
A star schema contains one, or at least very few, very large fact entities, plus a large number of small dimensional entities. As already stated, effectively fact entities contain transactional histories and dimension entities contain static data describing the fact entity archive entries. The objective for performance is to obtain joins on a single join level, where one fact entity is joined to multiple small dimension entities, or perhaps even a single dimension entity.
A snowflake schema is a normalized star schema such that dimension entities are normalized.
A single data warehouse can contain multiple fact entities and, therefore, multiple star schemas. Additionally, individual dimension entities can point to multiple fact entities. Dimension entities will occupy a small fraction of the storage space than fact entities do. Fact entities in a data warehouse can have trillions of rows, whereas dimensions are in the range of tens, hundreds or perhaps thousands. Any larger than thousands and those dimensions could possibly be facts.