Will an index on a column help in performance of a lookup
Lets say we are doing a lookup on the employee table which has - Empno, ename,salary
Now we want to check if the empno is present then update else insert. So we do a lookup on the table
The data resulted from the lookup query will be stored in the cache (index and data cache), each record from the source is looked up against this cache. Now checking against the condition port column is done in the Informatica Lookup cache and not in the database. Due to this any index created in the database has no effect or imporvement on the performance of the lookup.
Can we replicate the same index in Lookup Cache? We don't need to do this. PowerCenter create Index and Data cache for the Lookup. In our case, condition port data - "EMPNO" is indexed and hashed in Index cache and the rest data is found in Data cache.
Now let's consider another lookup case, disable lookup cache. In this kind of Lookup, there is no cache. Everytime a row is sent into lookup, the SQL is executed against database. In this case, the database index may work. But, if the performance of the lookup is a problem, then "cache-less" lookup itself may be a problem.
We should go for cache-less lookup if our source data record is less than the number of records in my lookup table. In this case ONLY, indexing the condition ports will work. Everywhere else, it is just a mere chanse of luck, that makes the database pick up index.
Putting a where condition in the lookup, fetching the minimum required rows in lookup definately adds up to the performance and should always be taken care of.
Happy caching !!
Showing posts with label ashjeet. Show all posts
Showing posts with label ashjeet. Show all posts
Thursday, December 17, 2009
Friday, December 4, 2009
How do you run a full DAC load
How do you run a full load (not incremental)
If DAC is running incremental everyday and due to some reason you want to do a full load then
You need to reset the Data Warehouse > DAC Client ver 7.9.5. Click on "Tools" --> "ETL Management" --> "Reset Data Warehouse" , it will prompt for
This action will cause all tables that are loaded during
next ETL to be truncated.
Do you want to proceed? >> Yes
This will truncate all the tables, drop indexes and do a full load of dimensions and facts then recreate indexes and compute stats.
What 'Reset Datawareshouse' does is it just updates last_refresh_dt of w_etl_refresh_dt to NULL.
The other way to do it is go to metadata tables and set the Last_refresh_dt to NULL
select row_wid,last_upd,dbconn_wid,ep_wid,table_name,last_refresh_dt,total_count,curr_process_count,version_id from w_etl_refresh_dt
update w_etl_refresh_dt set last_refresh_dt=NULL;
commit;
This will do a full DAC load.
If DAC is running incremental everyday and due to some reason you want to do a full load then
You need to reset the Data Warehouse > DAC Client ver 7.9.5. Click on "Tools" --> "ETL Management" --> "Reset Data Warehouse" , it will prompt for
This action will cause all tables that are loaded during
next ETL to be truncated.
Do you want to proceed? >> Yes
This will truncate all the tables, drop indexes and do a full load of dimensions and facts then recreate indexes and compute stats.
What 'Reset Datawareshouse' does is it just updates last_refresh_dt of w_etl_refresh_dt to NULL.
The other way to do it is go to metadata tables and set the Last_refresh_dt to NULL
select row_wid,last_upd,dbconn_wid,ep_wid,table_name,last_refresh_dt,total_count,curr_process_count,version_id from w_etl_refresh_dt
update w_etl_refresh_dt set last_refresh_dt=NULL;
commit;
This will do a full DAC load.
Oracle Hints
A hint is nothing more than a directive to change an execution plan
SELECT /*+ hint --or-- text */ statement body
SELECT /*+ hint --or-- text */ statement body
Thursday, December 3, 2009
Oracle Table Lock
-- Check Lock Table
select
c.owner,
c.object_name,
c.object_type,
b.sid,
b.serial#,
b.status,
b.osuser,
b.machine
from
v$locked_object a ,
v$session b,
dba_objects c
where
b.sid = a.session_id
and
a.object_id = c.object_id;
Do the following >>
select object_id from dba_objects where object_name='tablename';
select * from v$locked_object where object_id=id number;
Note the "oracle_username" and "session_id".
Or you can query v$access
select sid from v$access where owner='table owner' and object='table
name';
Note the session id number or "sid".
select sid, serial#, command, taddr from v$session where sid=session id
number;
Now you have identified the user and what they are doing.
To terminate the session:
Alter system kill session 'sid, serial#' immediate;
The session should now be killed and the lock SHOULD release.
Rechecking "v$locked_object" will tell you this. If the lock does not
immediately release, there may be a rollback occuring.
To check for rollback:
select used_ublk from v$transaction where ADDR=value from TADDR in
v$session;
select c.owner, c.object_name, c.object_type,b.sid, b.serial#, b.status, b.osuser, b.machine
from v$locked_object a , v$session b, dba_objects c
where b.sid = a.session_id
and a.object_id = c.object_id;
select
username,
v$lock.sid,
trunc(id1/power(2,16)) rbs,
bitand(id1,to_number('ffff','xxxx'))+0 slot,
id2 seq,
lmode,
request
from v$lock, v$session
where v$lock.type = 'TX'
and v$lock.sid = v$session.sid
and v$session.username = USER
select
c.owner,
c.object_name,
c.object_type,
b.sid,
b.serial#,
b.status,
b.osuser,
b.machine
from
v$locked_object a ,
v$session b,
dba_objects c
where
b.sid = a.session_id
and
a.object_id = c.object_id;
Do the following >>
select object_id from dba_objects where object_name='tablename';
select * from v$locked_object where object_id=id number;
Note the "oracle_username" and "session_id".
Or you can query v$access
select sid from v$access where owner='table owner' and object='table
name';
Note the session id number or "sid".
select sid, serial#, command, taddr from v$session where sid=session id
number;
Now you have identified the user and what they are doing.
To terminate the session:
Alter system kill session 'sid, serial#' immediate;
The session should now be killed and the lock SHOULD release.
Rechecking "v$locked_object" will tell you this. If the lock does not
immediately release, there may be a rollback occuring.
To check for rollback:
select used_ublk from v$transaction where ADDR=value from TADDR in
v$session;
select c.owner, c.object_name, c.object_type,b.sid, b.serial#, b.status, b.osuser, b.machine
from v$locked_object a , v$session b, dba_objects c
where b.sid = a.session_id
and a.object_id = c.object_id;
select
username,
v$lock.sid,
trunc(id1/power(2,16)) rbs,
bitand(id1,to_number('ffff','xxxx'))+0 slot,
id2 seq,
lmode,
request
from v$lock, v$session
where v$lock.type = 'TX'
and v$lock.sid = v$session.sid
and v$session.username = USER
Informatica Metadata
Informatica maintains metedata regarding the mappings and its tranformations, sessions, workflows and their statistics. These details are maintained in a set of tables called OPB tables and REP tables.
The widget refers to the types of transformation details stored in these tables.
Widget Ids and transformation types
widget_type Type of transformation
1 Source
2 Target
3 Source Qualifier
4 Update Strategy
5 expression
6 Stored Procedures
7 Sequence Generator
8 External Procedures
9 Aggregator
10 Filter
11 Lookup
12 Joiner
14 Normalizer
15 Router
26 Rank
44 mapplet
46 mapplet input
47 mapplet output
55 XML source Qualifier
80 Sorter
97 Custom Transformation
select z.widget_id, decode(z.porttype, 1, 'INPUT', 3, 'IN-OUT', 2, 'OUT', 32, 'VARIABLE', 8, 'LOOKUP', 10, 'OUT-LOOKUP', to_char(z.porttype)) Port_Type from opb_widget_field z;
If you want to know the mapping name, then match the widget_id against the widget_id of opb_widget_inst and then pull the mapping_id which can be mapped against mapping_id in opb_mappings table. If you want to know the Folder name, then map the subject_id from opb_mappings to that of subj_id in OPB_SUBJECTS table to get the subject_name.
OPB_EXPRESSION is the table that stores all the expressions in metadata. To associate an expression to a field in a transformation, OPB_WIDG_EXPR is the table to be used.
select g.expression from opb_widget_expr f, opb_expression g where f.expr_id = g.expr_id;
SQL overrides can be in Source Qualifiers and Lookup transformations.
To get the SQL Override from metadata, check REP_WIDGET_ATTR.ATTR_VALUE column.
select * from opb_widget_field where wgt_datatype=11
select g.expression from opb_widget_expr f, opb_expression g where f.expr_id = g.expr_id;
select * from REP_WIDGET_ATTR
select * from opb_mapping -- to check for mapping,mapplet, its stauts of valid/invalid etc
select * from opb_server_info -- to get server hostname,ip,etc
select src_id from opb_src where source_name ='W_DAY_D' -- source table , owner info
select * from opb_src_fld where src_id=1753 -- to get table column/field list info
select * from opb_targ where target_name like 'W_DAY_D' -- target table info
select * from opb_targ_fld where target_id =1835 -- to get target field info
The widget refers to the types of transformation details stored in these tables.
Widget Ids and transformation types
widget_type Type of transformation
1 Source
2 Target
3 Source Qualifier
4 Update Strategy
5 expression
6 Stored Procedures
7 Sequence Generator
8 External Procedures
9 Aggregator
10 Filter
11 Lookup
12 Joiner
14 Normalizer
15 Router
26 Rank
44 mapplet
46 mapplet input
47 mapplet output
55 XML source Qualifier
80 Sorter
97 Custom Transformation
select z.widget_id, decode(z.porttype, 1, 'INPUT', 3, 'IN-OUT', 2, 'OUT', 32, 'VARIABLE', 8, 'LOOKUP', 10, 'OUT-LOOKUP', to_char(z.porttype)) Port_Type from opb_widget_field z;
If you want to know the mapping name, then match the widget_id against the widget_id of opb_widget_inst and then pull the mapping_id which can be mapped against mapping_id in opb_mappings table. If you want to know the Folder name, then map the subject_id from opb_mappings to that of subj_id in OPB_SUBJECTS table to get the subject_name.
OPB_EXPRESSION is the table that stores all the expressions in metadata. To associate an expression to a field in a transformation, OPB_WIDG_EXPR is the table to be used.
select g.expression from opb_widget_expr f, opb_expression g where f.expr_id = g.expr_id;
SQL overrides can be in Source Qualifiers and Lookup transformations.
To get the SQL Override from metadata, check REP_WIDGET_ATTR.ATTR_VALUE column.
select * from opb_widget_field where wgt_datatype=11
select g.expression from opb_widget_expr f, opb_expression g where f.expr_id = g.expr_id;
select * from REP_WIDGET_ATTR
select * from opb_mapping -- to check for mapping,mapplet, its stauts of valid/invalid etc
select * from opb_server_info -- to get server hostname,ip,etc
select src_id from opb_src where source_name ='W_DAY_D' -- source table , owner info
select * from opb_src_fld where src_id=1753 -- to get table column/field list info
select * from opb_targ where target_name like 'W_DAY_D' -- target table info
select * from opb_targ_fld where target_id =1835 -- to get target field info
Friday, November 13, 2009
Data Warehouse Concepts - Part 2
Data warehouse is designed mainly to supply Information to the business to decide in a better and faster way based on analysis of historical data. So it is essential we model its Logical and Physical design in the best way. Physical design is mainly for the purpose of performance and functionality of the data warehouse and logical design is a way to capture and present the business requirements in the entity way.
In data modeling following tasks are performed in an iterative manner:
• Identify entity types
• Identify attributes
• Apply naming conventions
• Identify relationships
• Apply data model patterns
• Assign keys
• Normalize to reduce data redundancy (Entity Relationship Model)
• Denormalize to improve performance (Dimensional Model)
In data modeling following tasks are performed in an iterative manner:
• Identify entity types
• Identify attributes
• Apply naming conventions
• Identify relationships
• Apply data model patterns
• Assign keys
• Normalize to reduce data redundancy (Entity Relationship Model)
• Denormalize to improve performance (Dimensional Model)
Two types of data modeling are as follows:
· Logical modeling
· Physical modeling
· Logical modeling
· Physical modeling
Logical modeling deals with gathering business requirements and converting those requirements into a model. The logical model revolves around the needs of the business, not the database, although the needs of the business are used to establish the needs of the database. Logical modeling involves gathering information about business processes, business entities (categories of data), and organizational units. After this information is gathered, diagrams and reports are produced including entity relationship diagrams, business process diagrams, and eventually process flow diagrams. The diagrams produced should show the processes and data that exists, as well as the relationships between business processes and data. Logical modeling should accurately render a visual representation of the activities and data relevant to a particular business.
Typical deliverables of logical modeling include
Entity relationship diagrams :
An Entity Relationship Diagram is also referred to as an analysis ERD. The point of the initial ERD is to provide the development team with a picture of the different categories of data for the business, as well as how these categories of data are related to one another.
Business process diagrams :
Business process diagrams :
The process model illustrates all the parent and child processes that are performed by individuals within a company. The process model gives the development team an idea of how data moves within the organization. Because process models illustrate the activities of individuals in the company, the process model can be used to determine how a database application interface is design.
User feedback documentation :
User feedback documentation :
Physical modeling involves the actual design of a database according to the requirements that were established during logical modeling. Logical modeling mainly involves gathering the requirements of the business, with the latter part of logical modeling directed toward the goals and requirements of the database. Physical modeling deals with the conversion of the logical, or business model, into a relational database model. When physical modeling occurs, objects are being defined at the schema level. A schema is a group of related objects in a database. A database design effort is normally associated with one schema.
During physical modeling, objects such as tables and columns are created based on entities and attributes that were defined during logical modeling. Constraints are also defined, including primary keys, foreign keys, other unique keys, and check constraints. Views can be created from database tables to summarize data or to simply provide the user with another perspective of certain data. Other objects such as indexes and snapshots can also be defined during physical modeling. Physical modeling is when all the pieces come together to complete the process of defining a database for a business.
Physical modeling is database software specific, meaning that the objects defined during physical modeling can vary depending on the relational database software being used. For example, most relational database systems have variations with the way data types are represented and the way data is stored, although basic data types are conceptually the same among different implementations. Additionally, some database systems have objects that are not available in other database systems.
Typical deliverables of physical modeling include the following:
Server model diagrams:
The server model diagram shows tables, columns, and relationships within a database.
User feedback documentation :
User feedback documentation :
Database design documentation :
Designing the Data warehouse
Main emphasis in the design is on fast query retrieval rather than transactional performance. The design should be such that it enables analysis of data from any angle at any given point of time.
Dimensional Data Model is the best way of designing a data ware house. The main terms used in dimensional modeling are facts and dimensions.
1. Fact - A fact is a single iteration in a historical record
2. Dimension - A dimension is something used to dig into, divide, and collate those facts into something useful
Facts represent historical or archived data and dimensions represent smaller static data entities. It follows that dimension entities will generally be small and fact entities can become frighteningly huge. Fact entities will always be appended to, and dimension entities can be changed, preferably not as often as the fact entities are appended to. The result is many very small entities related to data in groups from very large entities.
Granularity
While designing a fact the most important point to keep in mind is the granularity, how much data to keep and to what level of detail. So do we need to store all transaction or do we store it at summary level. Like in case of a Retailer and Manufacturer, a Retailer would like to capture each and every piece of an item sold from its point of sale i.e. at the lowest Stock keeping unit level to maintain its inventory better, where as the Manufacturer might keep it at a level higher than the pieces, they would not need information of each piece sold, they might be interested to keep record at an Item level, one level above Stock keeping as compared to Retailers. So depending on business needs we need to decide the lowest possible granular level to be kept in facts to make the reporting accurate. From a planning perspective, it might be best to begin by retaining all facts down to the smallest detail if at all possible. Data warehouses are expected to be large, and disk space is cheap.
Star and Snow Flake Schema
A star schema contains one, or at least very few, very large fact entities, plus a large number of small dimensional entities. As already stated, effectively fact entities contain transactional histories and dimension entities contain static data describing the fact entity archive entries. The objective for performance is to obtain joins on a single join level, where one fact entity is joined to multiple small dimension entities, or perhaps even a single dimension entity.
A snowflake schema is a normalized star schema such that dimension entities are normalized.
A single data warehouse can contain multiple fact entities and, therefore, multiple star schemas. Additionally, individual dimension entities can point to multiple fact entities. Dimension entities will occupy a small fraction of the storage space than fact entities do. Fact entities in a data warehouse can have trillions of rows, whereas dimensions are in the range of tens, hundreds or perhaps thousands. Any larger than thousands and those dimensions could possibly be facts.
Tuesday, November 10, 2009
Data Warehouse Concepts : Part 1
Now that we have decided to work on data warehousing, let us try to have an understanding on what exactly is a data warehouse, how different it is from the existing other applications and what is the main purpose of any business to go for a data warehouse.
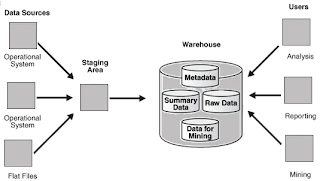
2. With Staging Area – We need to clean and process our operational data before putting it into the warehouse. A staging area simplifies building summaries and general warehouse management
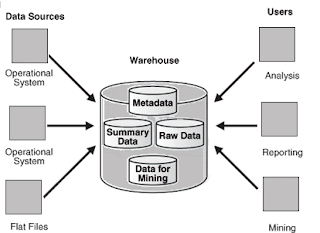
What is a Data Warehouse?
A data warehouse is a relational database that is designed for query and analysis rather than for transaction processing. It usually contains historical data derived from transaction data, but can include data from other sources like EBS, SAP, Siebel, apart from your existing OLTP system in use. Data warehouses is mainly used for analysis and is separate from transaction workload, it enables an organization to consolidate data from several sources to come up for a centralized place where analysis can be done faster and in a better way. This helps in:
1. Maintaining historical data
2. Analyzing the data to gain a better understanding of the business and to improve the existing business.
In addition to a relational database, a data warehouse environment can include an extraction, transportation, transformation, and loading (ETL) solution (depending on the type/tool it can be ETL,ELT or ETL solutions), statistical analysis, reporting, data mining , client analysis , and many other applications that manage the process of gathering data, transforming it into useful information and finally delivering it to business users.
Why is it different from the existing Transaction system - OLTP or transactional database is mainly used for the purpose of daily activity i.e. Insert/update/delete i.e. to store data for daily operational purpose. Data warehouse or OLAP system is on top of this - ie it takes data from OLTP and transforms it for the management to come up with analysis on it, reporting, ad hoc reports so that better decisions can be made, where as end user of an OLTP system is the Operational team who maintains the day to day activities of the business.
Lets take for example a railway ticket booking system - when I enter in irctc.co.in to book my ticket then the main purpose is to get a seat booked – Operational. For this the backend data model/tables/ physical objects have to be designed in such a way that it helps in easy and fast processing of Inert/Update and Deleting of data. The best way of doing this is to have a Normalized database model which is the OLTP system (On line transaction processing) which stores data in the 3NF form making the data transfer very fast. Now when I enter my information it goes at the back end in numerous tables which are in the 3NF form enabling my processing faster for a ticket booking, same is the case of ATM transaction, shopping anything related to Operational Data i.e. day to day transactions. After I have booked my ticket, my work is done. The railway helpdesk maintaining this – his work is done. We have a vast database which maintains daily data.
After this lets talk on the other side of the Railway department – the ministry now wants to come up with which routes are doing good, which are less profit making, which services are running in profit and where there a need for improvement. Lets take for example, the management wants reports like –
a. Most profit making route in terms of day/train/passenger wise
b. Least profit making route in terms of day/train/passenger wise
c. Monthly report on same line
d. Quarterly report on same line
e. Yearly report on same line
f. Comparison of this day to same day in history, this month to same month last year, this quarter to last quarter, to last year etc.
g. Comparison of two routes in terms of profit, maintenances , time lines
There can be numerous reports that the management might want to look at for analysis and decision making at any given point of time. There can be a need of ad hoc reports also which might be required for some important presentations, decisions.
For all of this to happen, imagine a team of reporting people struggling hard to make different joins, different source data, consolidating data, cleansing operational data, integrating them, making them as per the required subject areas on top of huge and vast set of tables, a network of tables which are in the 3NF form making it a non user friendly environment for understanding and working on. Even if there is an expert in Oracle lets say, but data is coming from Oracle, Teradata, db2 and sap for different lines, different regions. Employee data is in different source, different format, trains information is in different format. Imagine the amount of work required to consolidate this information and come up with joins etc to make simple reports. It will take years to implement this reporting requirement on an OLTP system and an expert team of each area. More work, more people, more time required at each level making it a very difficult and cumbersome job that too question to reliability and stability. How to get historical data from archive files, how to centralize data from different places, how to make meaning to all the tables
Now imagine a data warehouse on top of this - a denormalized model which will help in maintaining the historical data from different sources at a centralized place to make the reporting a very easy job. Lets take the OLTP data and on top of that build our data warehouse model – we can have a Star, Snow flake schema, or a hybrid schema to facilitate this. We will need to come up with a Logical data model and then Physical data model. All this will be done to come up with a model that will help in storing data in such a way that it is easily retrievable and gives fast report building and query execution state to make it the best way of reporting for the management which in turn can come up with better decision making for any organization.
So coming back to our example of Railway system – what all do we need. First is requirement gathering , assume completed. Then to make a data warehouse we need to consider its characteristic like –
1. Subject Oriented
2. Integrated
3. NonVolatile
4. Time Variant
Data Warehouse Architectures
Now that we have decided to have a data warehouse, we need to decide how our architecture will be out of the commonly used three forms
1. Basic – End users directly access data derived from several source systems through the data warehouse
2. With Staging Area – We need to clean and process our operational data before putting it into the warehouse. A staging area simplifies building summaries and general warehouse management

Wednesday, August 20, 2008
Data Warehouse Concepts
Hi ...
Will be posting Data warehouse Concepts, Management Concepts, Informatica , Oracle Warehouse Builder (OWB), SQL etc related topics here. Please feel free to add your comments/posts to share the knowledge among all.
Thanks,
Will be posting Data warehouse Concepts, Management Concepts, Informatica , Oracle Warehouse Builder (OWB), SQL etc related topics here. Please feel free to add your comments/posts to share the knowledge among all.
Thanks,
Subscribe to:
Posts (Atom)

